The KernelCI community continues to make great progress on multiple fronts of the project. Since our last update here, we have had two in-person events, a few technical achievements and new working groups launched. See detailed updates in the sections below.
Videos from Automated Testing Summit
KernelCI hosted the Automated Testing Summit(ATS) 2025 in Denver, CO, USA. It is co-located with the Open Source Summit North America. The event was great and we had many interesting discussions.
All the sessions were recorded and videos are available:
KernelCI Workshop in Amsterdam
In the last week of August, we hosted our first KernelCI workshop in a while. We had 12 participants in-person and a few who joined us online. The workshop was great to kick start some important discussions about the new KernelCI Architecture with the community.
During the workshop, we discussed how to fulfill maintainers’ use case, dealing with KernelCI labs issues, improving data quality and regression identification, KCIDB transition, RISC-V support and more. Check our notes and full video recording.

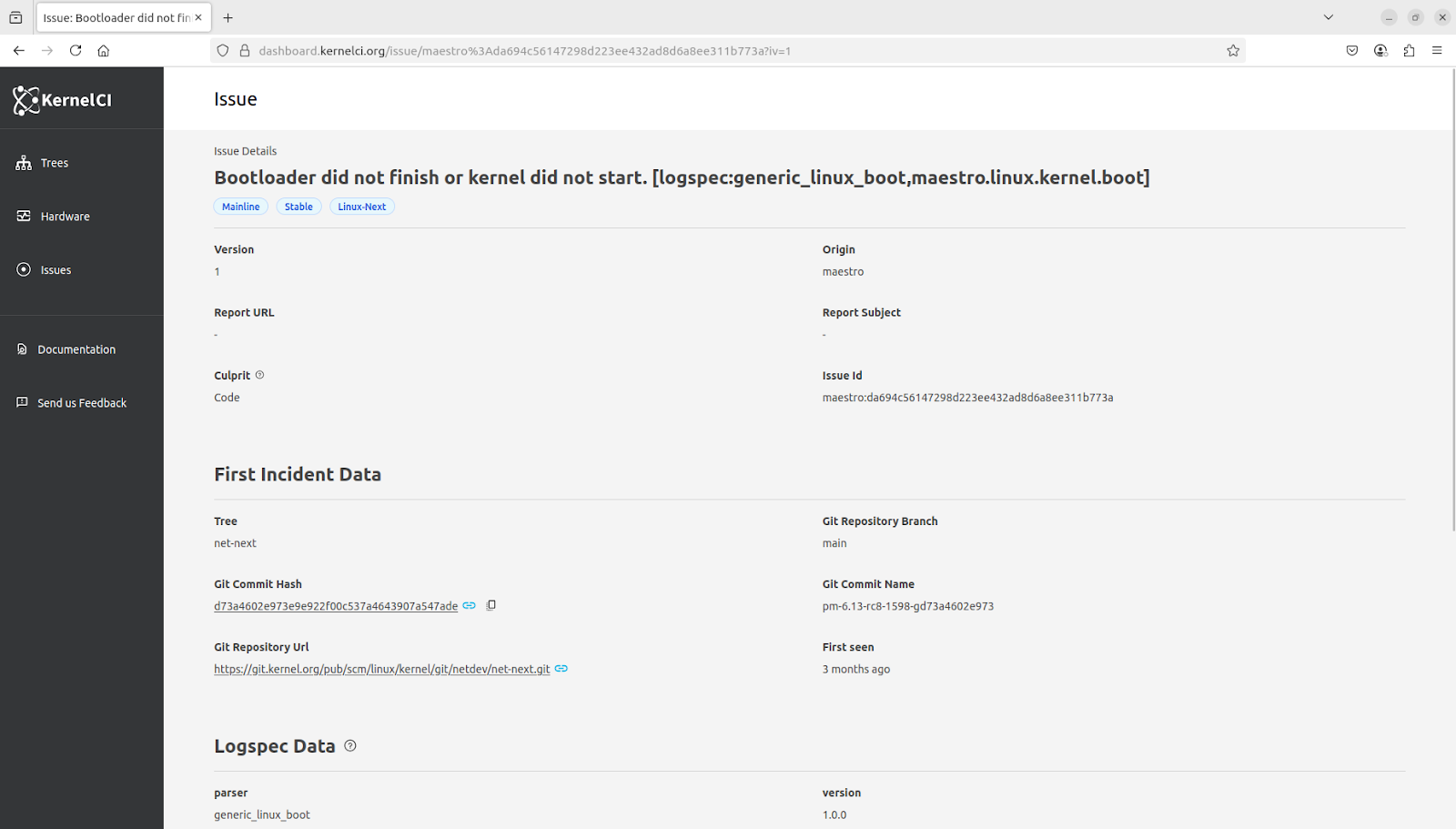
Transition out of legacy KCIDB
We finally completed our transition out of the legacy KCIDB. This was a very important step for the new KernelCI architecture. KCIDB is our common database for results, so on one end it has an API to receive test results white on the other is it as PostgreSQL database. The submission API has been supplanted by KCIDB-ng, but with no changes to the results submission JSON schema. Submitters are still sending the same files, but to a different API endpoint. KCIDB-ng is a fast Rust-based API to receive and store the JSON results files.
We’re transforming the KCIDB project into a more versatile, cloud-agnostic solution that can be deployed on-premise when needed. This flexibility allowed us to migrate KCIDB to Azure seamlessly. Additionally, we’ve rewritten portions of KCIDB in Rust, which has resolved longstanding performance bottlenecks.
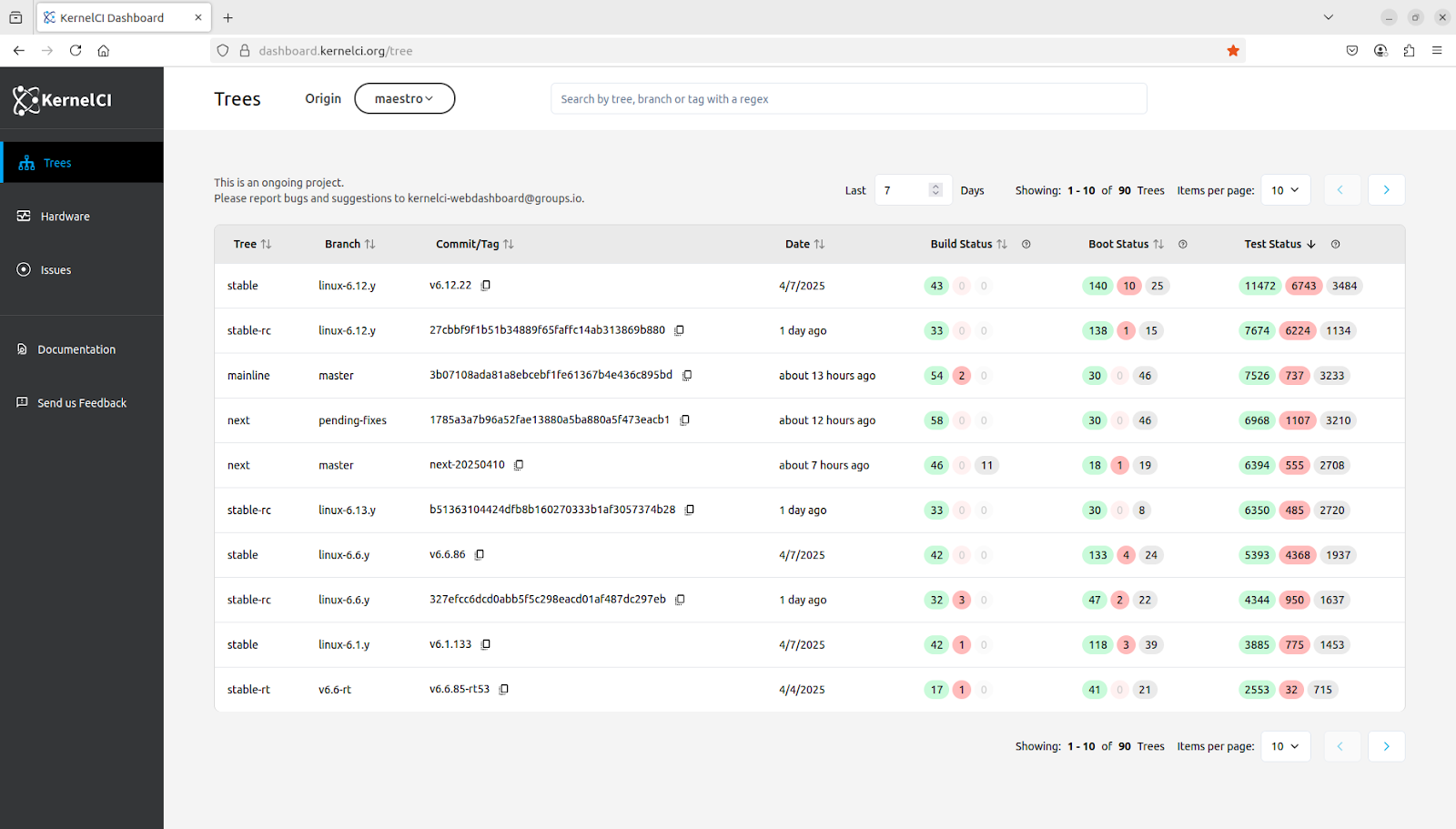
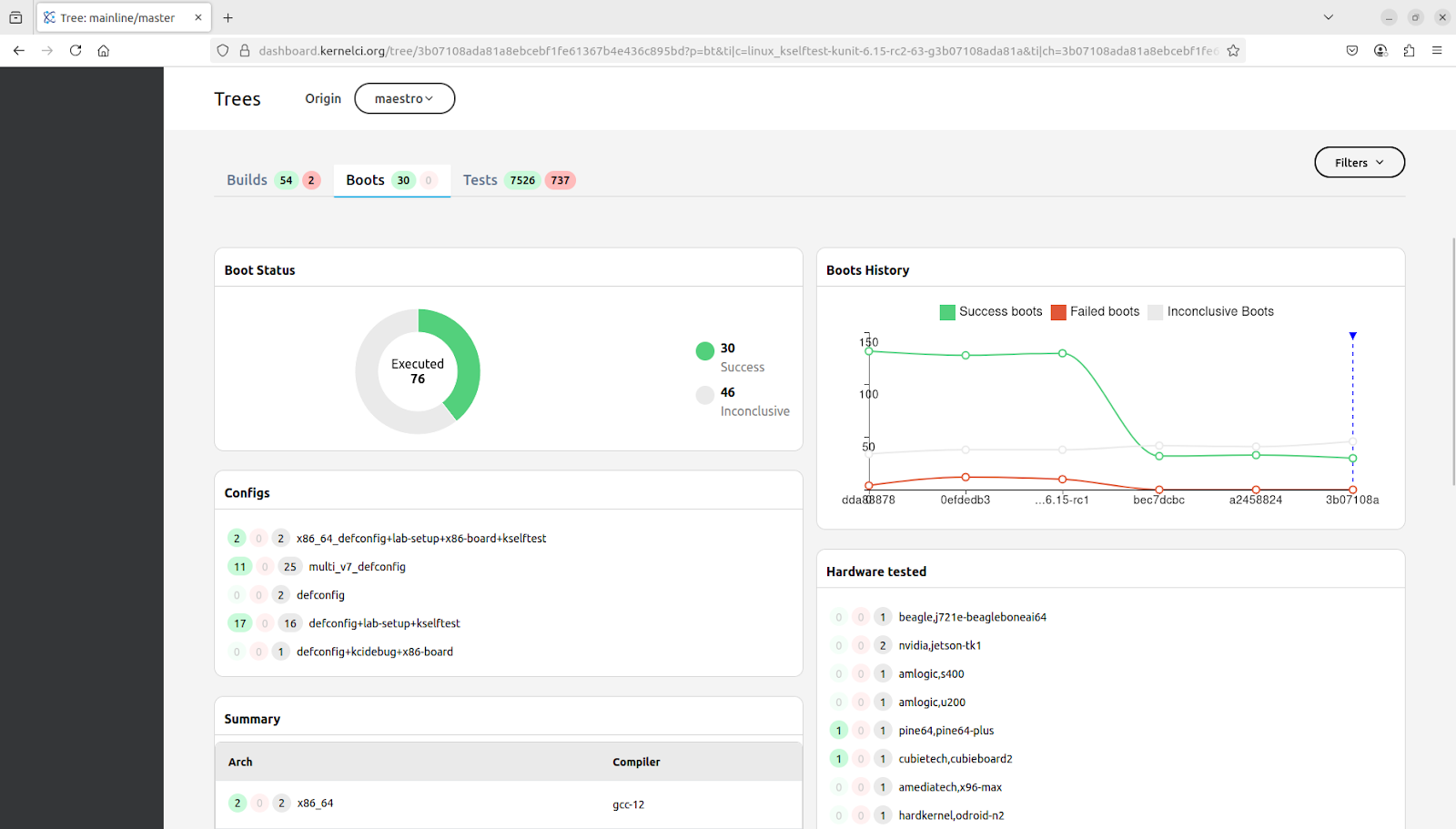
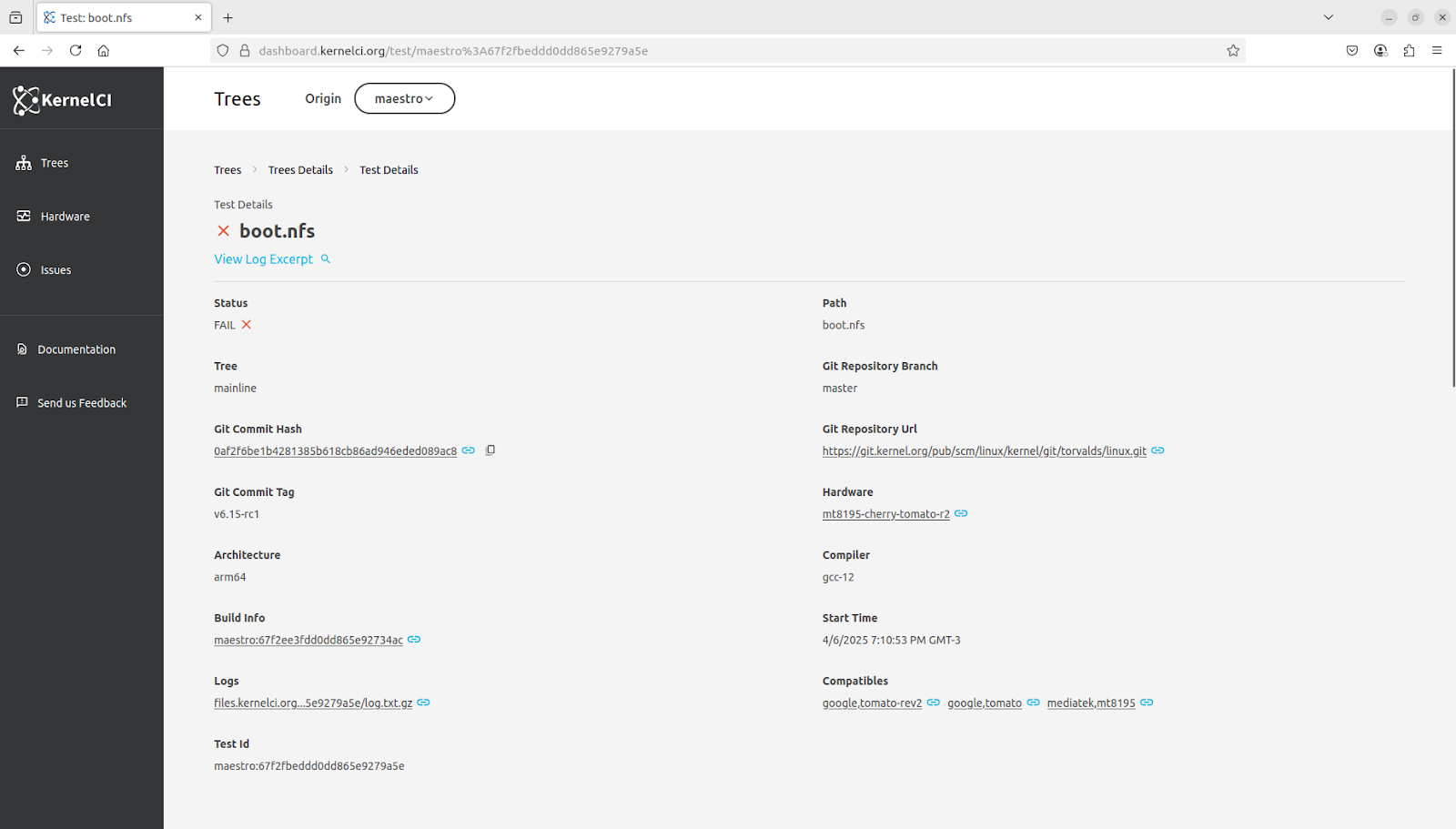
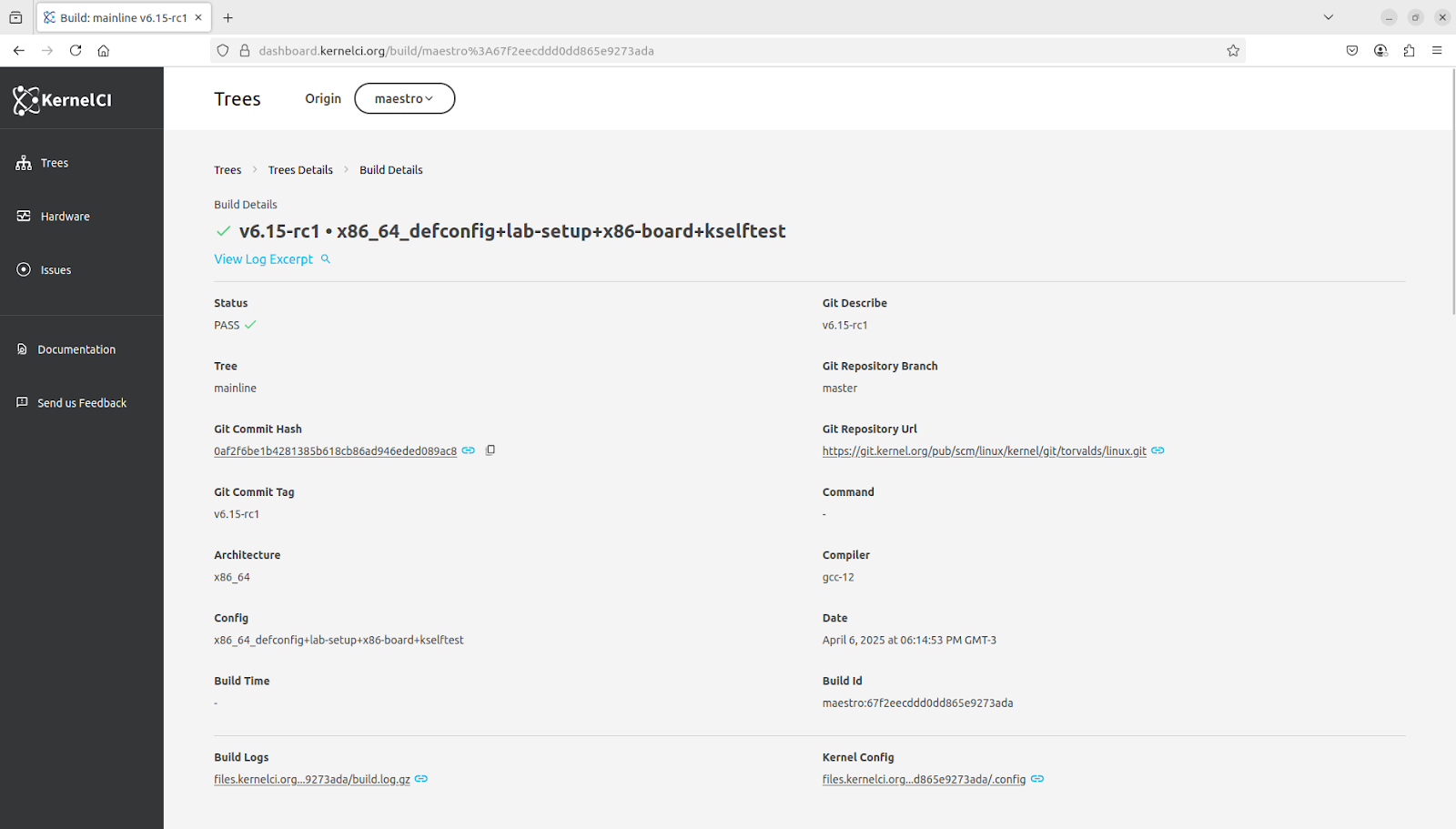
All the other responsibilities were handed over to our Dashboard, so it is responsible for processing and ingesting the data in the JSON files to our PostgreSQL database. The schema of the database remained the same as legacy
Core Infrastructure
Our new infrastructure has enabled us to significantly reduce complexity by implementing proper DevOps practices. Throughout Q3, we improved our deployment systems. In daily operations, this translates to production updates that require minimal supervision and minimal downtime – what previously took hours now takes less than one minute. We’ve also developed our own storage solution that gives us greater control over data costs by maintaining a “hot” cache on VMs while storing longer-term data in object storage with lifecycle policies and more economical storage classes.
There was also an effort to enhance monitoring and alerting systems to proactively prevent issues before they affect users. This includes implementing more granular metrics and establishing alerts for critical performance indicators.
These infrastructure improvements have collectively enabled us to scale more effectively, reduce operational costs, and enhance overall reliability. We remain committed to continuing our infrastructure investments to support our growing demands and ensure we can meet the needs of our expanding user base.
New Labs WG
As a great outcome from the KernelCI Workshop, we created the Labs Working Group(WG) to discuss challenges for connecting test labs to KernelCI.
The Labs WG is already a pretty busy space with over 10 people joining the calls in our bi-weekly sync. The current focus includes improving Maestro API for labs to pull test information from KernelCI, adding support for Labgrid and evaluating dashboards for lab metrics.
The team identified several key challenges that prevent labs from connecting to KernelCI. The primary obstacle is that many labs cannot expose their APIs to the public internet due to strict security policies. To address this limitation, we proposed a pull-mode architecture that reverses the traditional workflow – allowing labs to pull test jobs from KernelCI rather than having KernelCI push jobs directly to them. This approach enables labs to maintain their existing security policies while still actively participating in KernelCI testing. We’re currently developing the protocols and implementations necessary to support this pull-mode architecture.
Dashboard WG
Inspired by the Labs WG, we started the KernelCI Dashboard Working Group (first invite), gathering users and the development team from ProFUSION to talk about bugs and features prioritization.
In two meetings, with 8 attendees, we have defined an action plan to improve the performance of the website, which was affecting user experience, stopped the development of a feature that did not spark joy, and defined the next target for the team: Handling hardware data from labs. Which will require more discussions regarding how that data could be used by the users.
kci-dev improvements
kci-dev has evolved from a small command-line tool into a well-packaged suite of tools that Linux distributions can ship, aimed at analyzing KernelCI results and helping engineers triage problems quickly.
We had many improvements to the project in the past quarter:
- Added Debian/RPM packaging and OBS workflows/services automation so labs can build and publish updates automatically, so every client gets the same, reproducible toolchain.
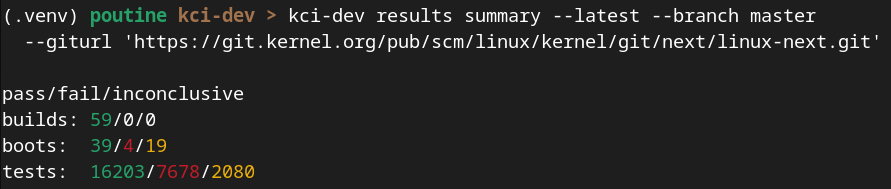
- Added results compare command for commit-to-commit regression detection (with tables + JSON output as well).
- Consolidated results issues group to list/show issues and fetch related builds/tests.
- Improved tree-level views with tree-report.
- Added code coverage information through new maestro coverage flow (currently only for chromiumos trees) with per-day buckets, a graph view, and report-info helpers, making stability/coverage trends far clearer.
- Improved validation tooling filters (arch filter; better build selection and considering build/job retry during validation). The validation commands allows us to compare if the tests Maestro is running are landing properly in KCIDB.
- Added –history to results summary.
- Fixed results hardware list and added more filters.
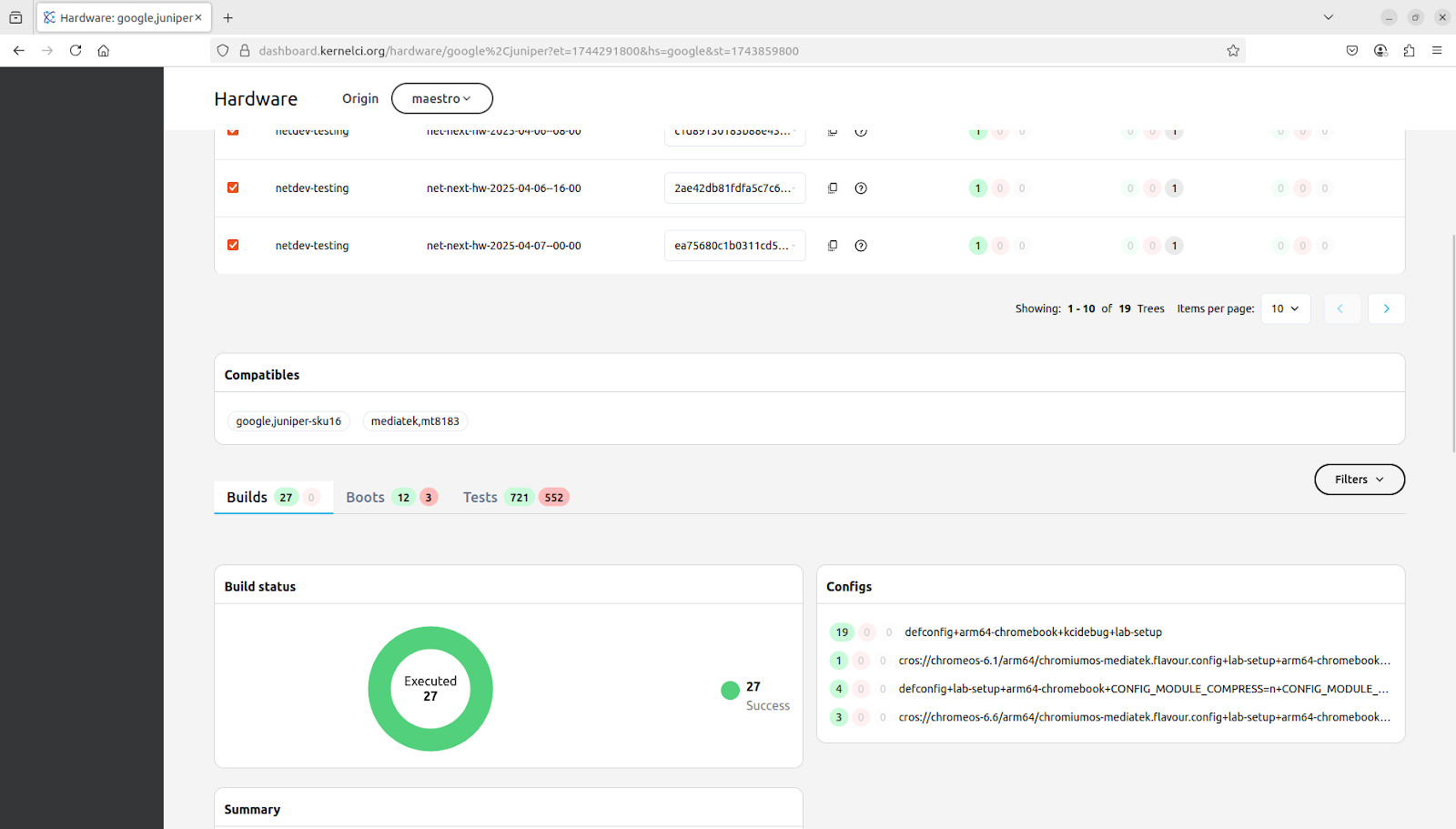
Hardware Information Registry
One of the challenges discussed in various KernelCI forums has been the inconsistency of hardware platform names reported from different testing labs, making it challenging to find/sort/filter results. To address this, a new YAML-based schema has been proposed by Minas Hambardzumyan and is currently in review. The schema organizes information into lists of platforms, processors, and vendors — providing a path to standardization of the reported platform names and adding traceability to product/vendor web pages for more information.
Final Thoughts
We will keep working on making KernelCI easier for the community to benefit from. From greater stability to an improved Web Dashboard and a more complete kci-dev CLI, there’s much more to enhance in KernelCI for everyone. Big thank you to the entire KernelCI community for making this progress possible!Talk to us at kernelci@lists.linux.dev , #kernelci IRC channel at Libera.chat or through our Discord server!
Contributed to this blog post Arisu Tachibana, Denys Fedoryshchenko, Gustavo Padovan, Minas Hambardzumyan and Tales Aparecida.