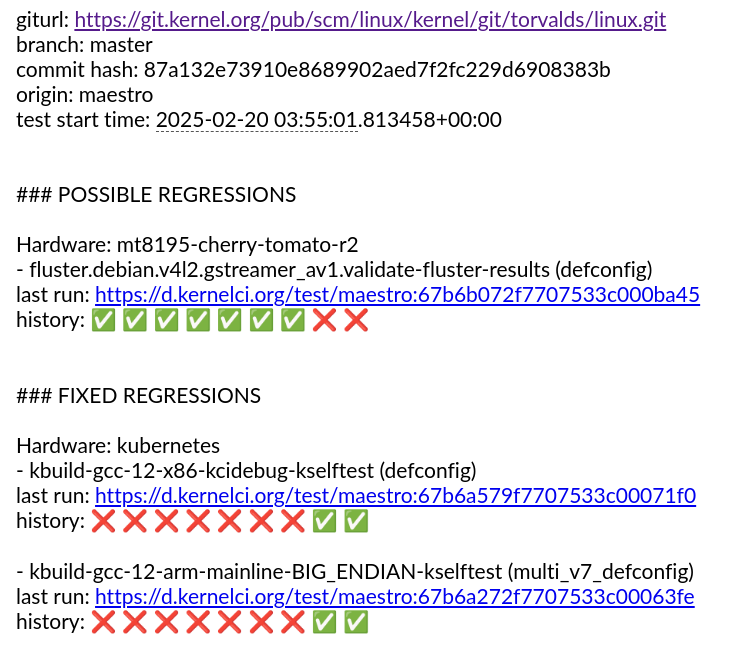
A lot has happened in KernelCI since our last blog update. The community continues to grow with Linaro and ELISA joining as members and more contributors and companies adding test results. The infra as a whole continues to evolve. And we are in the first stages of the development of the kernelci.yml test plan standard.
Linaro and ELISA joined us a members
Linaro is joining as a Premier member and ELISA as an Associate Member. We thank you both for their commitment to take part in the KernelCI community and join us in our mission to ensure the quality, stability and long-term maintenance of the Linux kernel.
“Linaro is excited to be rejoining the KernelCI project. KernelCI’s mission to provide Linux Kernel developers with testing at scale across a diverse set of platforms is key to ensuring the long term quality, reliability and security of the Linux kernel. Linaro looks forward to helping KernelCI to grow and become an even more valuable resource.” said Grant Likely, Linaro CTO.
“Linking the requirements to the tests will enable more efficiency in regression testing,” said Kate Stewart, Vice President of Dependable Embedded Systems at the Linux Foundation. “Being able to connect the traceability between code, requirements and tests will get us closer to improving the code coverage and quality of the Linux kernel images. The ELISA Project is focusing on kernel requirements and is looking forward to working with the KernelCI community to make the regression testing more effective over time.”
Automated Testing Summit coming up
KernelCI is hosting the Automated Testing Summit(ATS) 2025 in Denver, CO, USA. It is co-located with the Open Source Summit North America. The agenda is out and a presentation from KernelCI bringing you the latest project updates is on the schedule.
There is still time to sign up and meet us there. It is a hybrid event, so both in-person and virtual attendees are welcome.
Qualcomm, RISC-V International and Texas Instruments International submitting results
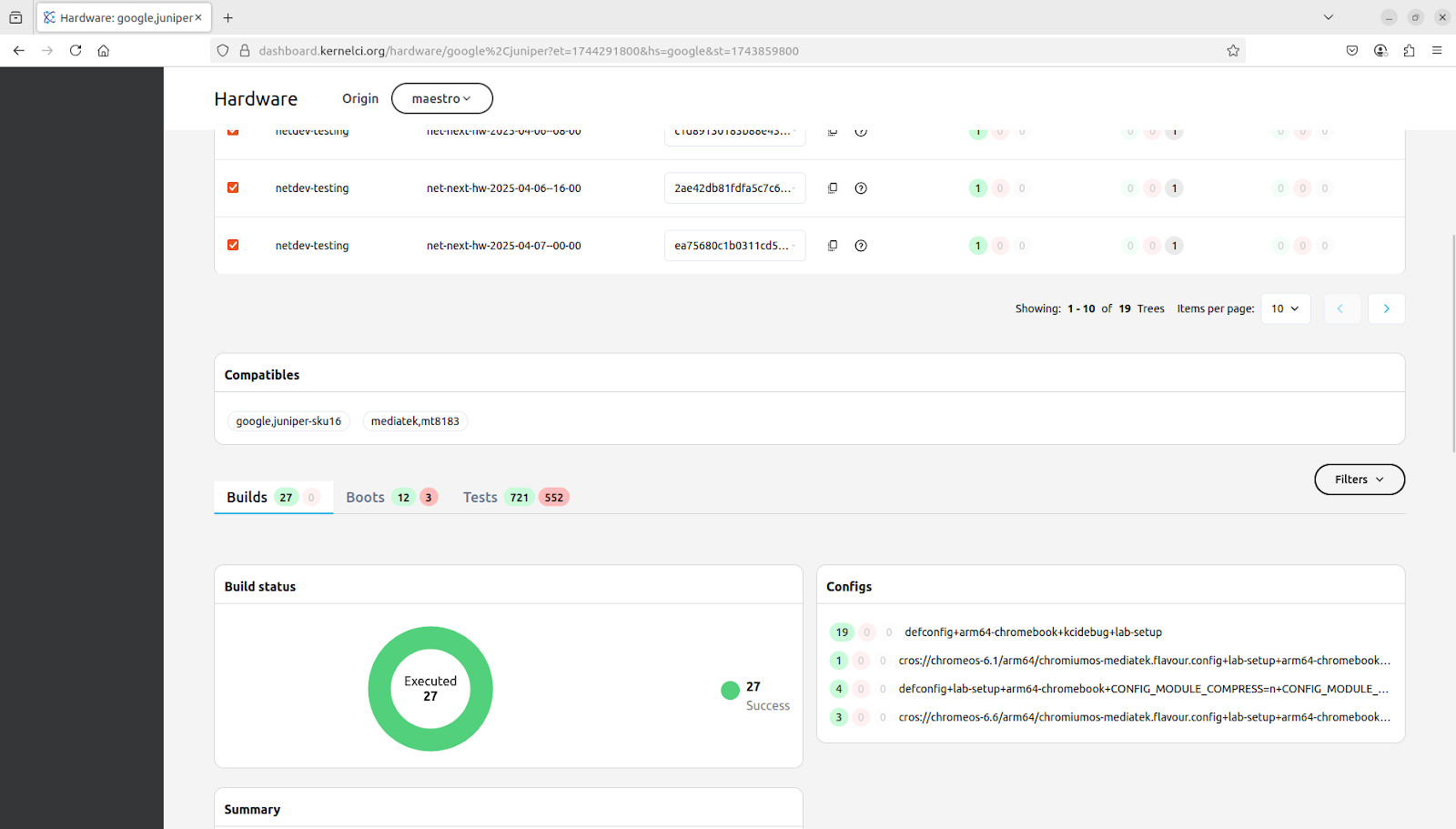
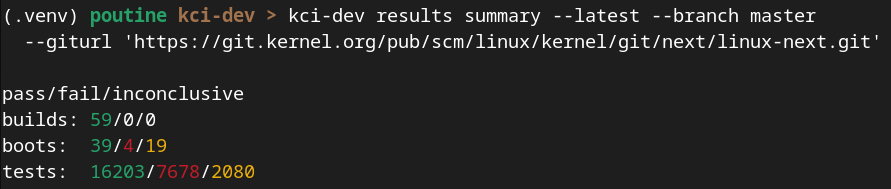
KernelCI gained data from 3 new submitters. Both Qualcomm, RISC-V International and Texas Instruments connected their test systems to KernelCI. If you look at our architecture, they are part of our CI ecosystem. They start off by listening to new build events from Maestro, then they download the binaries for the built kernel and artifacts from Maestro. With the kernel and artifacts, they can execute the testing on their environment – sometimes hidden behind a firewall. When tests are completed, they submit complete results to KCIDB, which then becomes accessible through our Dashboard and kci-dev.
.kernelci.yml test plan
We are proposing to introduce a standardized .kernelci.yml file in upstream kernel repositories to help the KernelCI community automatically discover and configure testing for each kernel tree. Part of the goal is to also transfer the ownership of the test plan by maintaining such files close to them or inside their subsystem folder.
This YAML file would specify branches to be tested, kernel configs to build, tests to execute, etc, enabling project maintainers to directly declare their KernelCI preferences. The main benefit is reducing manual effort and guesswork currently involved in onboarding new trees to KernelCI, ultimately making kernel testing more scalable, transparent, and easier to maintain for both KernelCI maintainers and kernel developers.
KCIDB-ng
With the amount of test results data received by KernelCI everyday growing, KCIDB started to show wear off signs. To address the limitations, including a previous implementation heavily dependent on specific Google Cloud technologies, we created kcidb-ng. The new project brings a system that is easy to deploy not only locally for development but also can be run on any cloud environment. It also simplified a lot the ingestion process.
Essentially, we have an API that receives json files with the test result content and stores the files in the spool directory. This entrypoint was written in Rust for efficiency. Then, we have an ingester looping in the server taking the files and ingesting them into PostgreSQL.
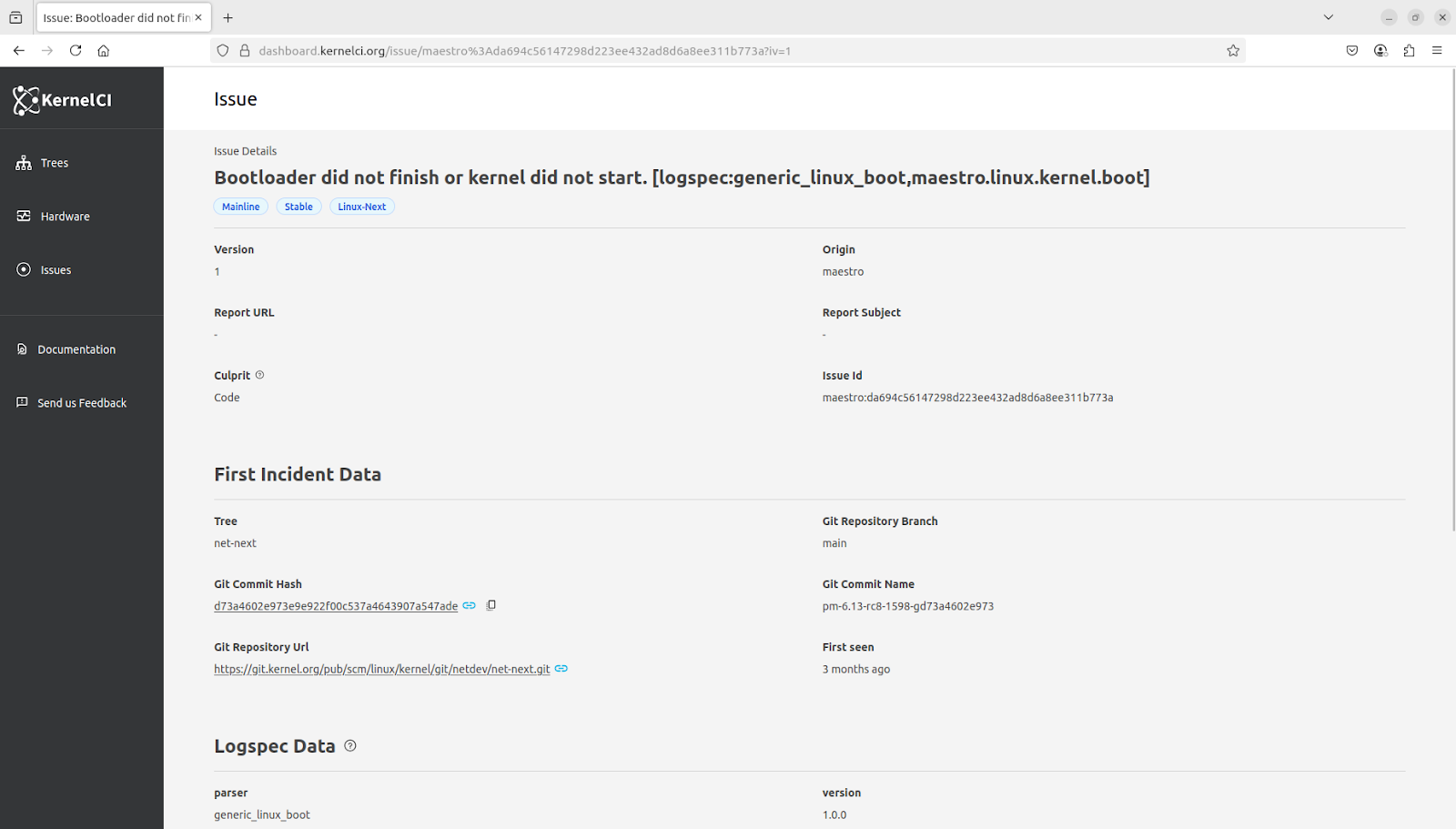
Additionally, kcidb-ng comes with logspec integration out of the box. So now data from any origin can be parsed to generate insights about build and test failures to generate KCIDB issue objects. The issues objects are the bridge between seeing a test failures and being able to report it as a regression to the community.
Right now, we are working with all KCIDB origins to move them over to the new API.
Strengthening core infra
Behind the scenes, we’ve been working hard to optimize our infrastructure costs and performance. Our build times on Azure build cluster improved dramatically from 88 to 17 minutes after migrating to modern D8lds_v6 instances, while actually reducing costs. We also implemented a caching solution for linux-firmware that cut our data egress costs by over 95% – from a projected $69k annually down to manageable levels. These optimizations mean faster feedback for developers and more sustainable operations for the project. Additionally, we’ve begun migrating KCIDB components to more cost-effective cloud services, starting with kcidb-rest, which will help us maintain reliable service while keeping infrastructure costs under control.
Final thoughts
We will keep working on making KernelCI easier for the community to benefit from. From greater stability to an improved Web Dashboard and a more complete kci-dev CLI, there’s much more to enhance in KernelCI for everyone. Big thank you to the entire KernelCI community for making this progress possible!Talk to us at kernelci@lists.linux.dev , #kernelci IRC channel at Libera.chat or through our Discord server!